//下面这个函数依题面而异,本题求解simpson求解宽度为w,高度为h的抛物线长度 doublesolve(double w,double h){ a = 4.0 * h / (w*w); //修改全局变量a,从而改变F的行为 returnasr(0,w/2,1e-5)*2; }
intmain(){ int t,cas = 0; scanf("%d", &t); while (cas++<t){ int D,H,B,L; scanf("%d%d%d%d", &D, &H, &B, &L); int n = (B+D-1) / D; double D1 = (double) B / n; double L1 = (double) L / n; double x = 0, y = H; while(y-x > 1e-5){//二分求解高度 double m = x + (y-x) / 2; if(solve(D1,m) < L1) x = m; else y = m; } if(cas > 1) puts(""); printf("Case %d:n%.2fn", cas, H - x); }
<span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">If we use the Newton-Raphson method for finding roots of the polynomial we need to evaluate both </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> and its derivative </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> for any </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">.</span>
It is often important to write efficient algorithms to complete a project in a timely manner. So let us try to design the algorithm for evaluating a polynomial so it takes the fewest flops (floating point operations, counting both additions and multiplications). For concreteness, consider the polynomial
<span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">The most direct evaluation computes each monomial </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> one by one. It takes </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> multiplications for each monomial and </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">additions, resulting in </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> flops for a polynomial of degree </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">. That is, the example polynomial takes three flops for the first term, two for the second, one for the third, and three to add them together, for a total of nine. If we reuse </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">from monomial to monomial we can reduce the effort. In the above example, working backwards, we can save </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> from the second term and get </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> for the first in one multiplication by </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">. This strategy reduces the work to </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> flops overall or eight flops for the example polynomial. For short polynomials, the difference is trivial, but for high degree polynomials it is huge. A still more economical approach regroups and nests the terms as follows: </span>
<span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">(Check the identity by multiplying it out.) This procedure can be generalized to an arbitrary polynomial. Computation starts with the innermost parentheses using the coefficients of the highest degree monomials and works outward, each time multiplying the previous result by </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;"> and adding the coefficient of the monomial of the next lower degree. Now it takes </span><span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">flops or six for the above example. This is the efficient </span>**Horner's algorithm**<span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">.</span>
<span style="color: rgb(0, 0, 0); font-family: Arial; font-size: 14.399999618530273px; line-height: 26px;">还有一个网站:</span>[http://www.wutianqi.com/?p=1426](http://www.wutianqi.com/?p=1426)
voidadd(int x,int times){ int hash = x % N; for (edge*t=ls[hash];t;t=t->next) if(t->key == x) return ; g[++e].key = x; g[e].times = times; g[e].next = ls[hash]; ls[hash] = &g[e]; }
intIn(int x){ int hash = x % N; for (edge*t=ls[hash];t;t=t->next) if(t->key == x) return t->times; return-1; }
intPower_mod(int a,int b,int mod){ llg t = a, res = 1; while (b){ if (b&1) res = res * t % mod; t = t * t % mod; b >>= 1; } return (int)(res); }
llg exgcd(int a,int b,llg &x,llg &y){ if (b == 0){ x = 1; y = 0; return a; } llg g = exgcd(b,a%b,x,y); llg tx = x,ty = y; x = ty; y = tx - a/b*ty; return g; }
intsolve(int a,int c,int p){ if (c >= p) return-1; int i,j; int x = 1; int t = 1; int s = (int)ceil(sqrt((double)p)); int res,cnt = 0; llg tx,ty,g; for (int i = 0; i <= 50; i++) if (Power_mod(a,i,p) == c) return i;
while ((g=exgcd(a,p,tx,ty)) != 1){ if (c%g) return-1; c /= g; p /= g; x = (llg)(a)/g*x%p; cnt ++; }
e = 0; memset(ls,0,sizeof(ls)); for (i = 0; i < s; i++) add(Power_mod(a,i,p),i);
for (int step = Power_mod(a,s,p),i = cnt; i < p; i += s,x = (llg)(x) * step % p){ g = exgcd(x,p,tx,ty); tx = tx * c % p; if (tx < 0) tx += p; res = In((int)tx); if (res == -1) continue; return res + i; } return-1; } }Number_Theory;
intmain(){ int a,p,c; while(~scanf("%d%d%d", &a, &p, &c)){ int ans = Number_Theory.solve(a,c,p); if (ans == -1) puts("Orz,I can’t find D!"); elseprintf("%dn", ans); } return0; }
structLinearProgramming{ int basic[maxn], row[maxn], col[maxn]; double c0[maxn];
doubledcmp(double x){ if (x > eps) return1; elseif (x < -eps) return-1; return0; } voidinit(int n, int m, double c[], double a[maxn][maxn], double rhs[], double &ans){ //初始化 for(int i = 0; i <= n+m; i++) { for(int j = 0; j <= n+m; j++) a[i][j]=0; basic[i]=0; row[i]=0; col[i]=0; c[i]=0; rhs[i]=0; } ans=0; } //转轴操作 intPivot(int n, int m, double c[], double a[maxn][maxn], double rhs[], int &i, int &j){ double min = inf; int k = -1; for (j = 0; j <= n; j ++) if (!basic[j] && dcmp(c[j]) > 0) if (k < 0 || dcmp(c[j] - c[k]) > 0) k = j; j = k; if (k < 0) return OPTIMAL; for (k = -1, i = 1; i <= m; i ++) if (dcmp(a[i][j]) > 0) if (dcmp(rhs[i] / a[i][j] - min) < 0){ min = rhs[i]/a[i][j]; k = i; } i = k; if (k < 0) return UNBOUNDED; elsereturn PIVOT_OK; } intPhaseII(int n, int m, double c[], double a[maxn][maxn], double rhs[], double &ans, int PivotIndex){ int i, j, k, l; double tmp; while(k = Pivot(n, m, c, a, rhs, i, j), k == PIVOT_OK || PivotIndex){ if (PivotIndex){ i = PivotIndex; j = PivotIndex = 0; } basic[row[i]] = 0; col[row[i]] = 0; basic[j] = 1; col[j] = i; row[i] = j; tmp = a[i][j]; for (k = 0; k <= n; k ++) a[i][k] /= tmp; rhs[i] /= tmp; for (k = 1; k <= m; k ++) if (k != i && dcmp(a[k][j])){ tmp = -a[k][j]; for (l = 0; l <= n; l ++) a[k][l] += tmp*a[i][l]; rhs[k] += tmp*rhs[i]; } tmp = -c[j]; for (l = 0; l <= n; l ++) c[l] += a[i][l]*tmp; ans -= tmp * rhs[i]; } return k; } intPhaseI(int n, int m, double c[], double a[maxn][maxn], double rhs[], double &ans){ int i, j, k = -1; double tmp, min = 0, ans0 = 0; for (i = 1; i <= m; i ++) if (dcmp(rhs[i]-min) < 0){min = rhs[i]; k = i;} if (k < 0) return FEASIBLE; for (i = 1; i <= m; i ++) a[i][0] = -1; for (j = 1; j <= n; j ++) c0[j] = 0; c0[0] = -1; PhaseII(n, m, c0, a, rhs, ans0, k); if (dcmp(ans0) < 0) return INFEASIBLE; for (i = 1; i <= m; i ++) a[i][0] = 0; for (j = 1; j <= n; j ++) if (dcmp(c[j]) && basic[j]){ tmp = c[j]; ans += rhs[col[j]] * tmp; for (i = 0; i <= n; i ++) c[i] -= tmp*a[col[j]][i]; } return FEASIBLE; } //standard form //n:原变量个数 m:原约束条件个数 //c:目标函数系数向量-[1~n],c[0] = 0; //a:约束条件系数矩阵-[1~m][1~n] rhs:约束条件不等式右边常数列向量-[1~m] //ans:最优值 x:最优解||可行解向量-[1~n] intsimplex(int n, int m, double c[], double a[maxn][maxn], double rhs[], double &ans, double x[]){ int i, j, k; //标准形式变松弛形式 for (i = 1; i <= m; i ++){ for (j = n+1; j <= n+m; j ++) a[i][j] = 0; a[i][n+i] = 1; a[i][0] = 0; row[i] = n+i; col[n+i] = i; } k = PhaseI(n+m, m, c, a, rhs, ans); if (k == INFEASIBLE) return k; k = PhaseII(n+m, m, c, a, rhs, ans, 0); for (j = 0; j <= n+m; j ++) x[j] = 0; for (i = 1; i <= m; i ++) x[row[i]] = rhs[i]; return k; } }ps; //Primal Simplex
int n,m; double c[maxn], ans, a[maxn][maxn], rhs[maxn], x[maxn];
intmain(){ while(scanf("%d %d", &n, &m) != EOF){ double ans; ps.init(n, m, c, a, rhs, ans); for (int i = 1; i <= n; i ++) scanf("%lf", &c[i]); for (int i = 1; i <= m; i ++){ for (int j = 1; j <= n; j ++){ scanf("%lf", &a[i][j]); } scanf("%lf", &rhs[i]); } int hehe=ps.simplex(n,m,c,a,rhs,ans,x); printf("Nasa can spend %.0f taka.n", ceil(m*ans)); } return0; }
voidfloyd() { for (int k = 1; k <= n; k++) for (int i = 1; i <= n; i++) for (int j = 1; j <= n; j++) { edge[i][j] = max(edge[i][j],min(edge[i][k],edge[k][j])); } }
intmain(){ int co = 0,w; char s1[100],s2[100]; while (scanf("%d%d", &n, &m) && (m + n)){ getchar(); num = 1; for (int i = 1; i <= n; ++i) for (int j = 1; j <= n; j++) edge[i][j] = 0; for (int i = 1; i <= m; ++i) { scanf("%s%s%d", s1, s2, &w);getchar(); int x = query(s1); int y = query(s2); edge[x][y] = w; edge[y][x] = w; } floyd(); scanf("%s%s",s1,s2); int x = query(s1); int y = query(s2); printf("Scenario #%dn%d tonsnn", ++co, edge[x][y]); } return0; }
voidsolve(int n){ if(n<=1) return ; for (int i = n; i > 0; i /= 5){ int p = i/10,q = i%10; co3 += p + (int)(q>=3); co5 += p + (int)(q>=5); co7 += p + (int)(q>=7); co9 += p + (int)(q>=9); } co2 += n/2; solve(n/2); }
void Modify(int x, int y, int delta) { for(int i = x; i <= N; i += lowbit(i)) for(int j = y; j <= N; j += lowbit(i)) C[x][y] += delta; }</pre>
<pre class="brush:cpp">
int Sum(int i, int j) { int ret = 0; for(int x = i; x > 0; x -= lowerbit(x)) { for(int y = j; y > 0; y -= lowerbit(y)) { ret += C[x][y]; } } return ret; }</pre>
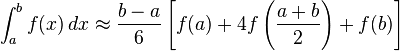 (感谢维基百科)
(感谢维基百科)