1. 使用自我学习到深层网络模型
在自我学习中,我们首先利用未标注数据训练一个稀疏自编码器。随后,给定一个新样 x,我们通过隐含层提取出特征 a。如下所示
我们感兴趣的是分类问题,目标是预测样本的类别标号 y。我们拥有标注数据集 $\{ (x_l^{(1)}, y^{(1)}), (x_l^{(2)}, y^{(2)}), \ldots (x_l^{(m_l)},y^{(m_l)}) \} ,包含 $m_l$ 个标注样本。此前我们已经说明,可以利用稀疏自编码器获得的特征 $a^{(l)} 来替代原始特征。这样就可获得训练数据集 $ \{ (a^{(1)},y^{(1)}), \ldots (a^{(m_{l})}, y^{(m_l)}) \} $。最终,我们训练出一个从特征 $a^{(i)}$ 到类标号 $y^{(i)}$ 的 logistic 分类器。为说明这一过程,我们按照神经网络一节中的方式,用下图描述 logistic 回归单元(橘黄色)。
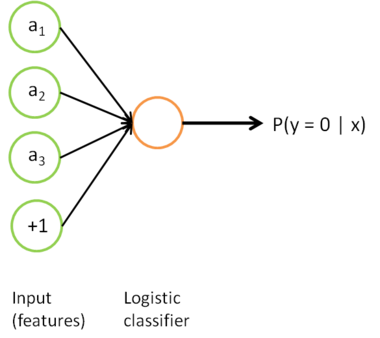
考虑利用这个方法所学到的分类器(输入-输出映射)。它描述了一个把测试样本 x 映射到预测值 $ p(y=1|x) $的函数。将此前的两张图片结合起来,就得到该函数的图形表示。最终的分类器就是: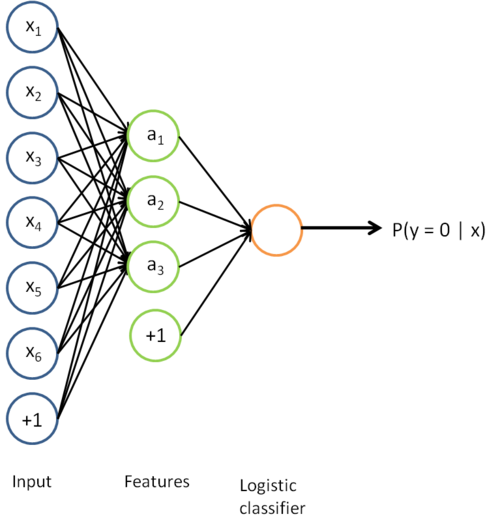
该模型的参数通过两个步骤训练获得:在该网络的第一层,将输入 x 映射至隐藏单元激活量 a 的权值$ W^{(1)} $可以通过稀疏自编码器训练过程获得。在第二层,将隐藏单元 a 映射至输出 y 的权值$ W^{(2)} $可以通过 logistic 回归或 softmax 回归训练获得。
这个最终分类器整体上显然是一个大的神经网络。因此,在训练获得模型最初参数(利用自动编码器训练第一层,利用 logistic/softmax 回归训练第二层)之后,我们可以进一步修正模型参数,进而降低训练误差。具体来说,我们可以对参数进行微调,在现有参数的基础上采用梯度下降或者 L-BFGS 来降低已标注样本集$ \{ (x_l^{(1)}, y^{(1)}), (x_l^{(2)}, y^{(2)}), \ldots (x_l^{(m_l)}, y^{(m_l)}) \} $上的训练误差。
使用微调时,初始的非监督特征学习步骤(也就是自动编码器和logistic分类器训练)有时候被称为预训练。微调的作用在于,已标注数据集也可以用来修正权值$ W^{(1)}$,这样可以对隐藏单元所提取的特征 a 做进一步调整。
目前我们使用的都是“替代”,并没有使用“级联”。替代中,logistics分类器所看到的训练样本格式为 $ (a^{(i)}, y^{(i)})$;而在级联表示中,分类器所看到的训练样本格式为 $ ((x^{(i)}, a^{(i)}), y^{(i)})$。
一般如果要进行微调的时候,采用替代,因为级联慢。而且通常是有大量已标注训练数据的情况下。微调能显著提升分类器性能。然而只有相对较少的已标注训练集,微调的作用就很有限了。
2. 深度网络概览
你目前构建了一个包括输入层、隐藏层以及输出层的三层神经网络。虽然该网络对于MNIST手写数字数据库非常有效,但是它还是一个非常“浅”的网络。这里的“浅”指的是特征(隐藏层的激活值 $ {a}^{(2)}$)只使用一层计算单元(隐藏层)来得到的。
深度神经网络,即含有多个隐藏层的神经网络。通过引入深度网络,我们可以计算更多复杂的输入特征。因为每一个隐藏层可以对上一层的输出进行非线性变换,因此深度神经网络拥有比“浅层”网络更加优异的表达能力(例如可以学习到更加复杂的函数关系)。
值得注意的是当训练深度网络的时候,每一层隐层应该使用非线性的激活函数f(x)。这是因为多层的线性函数组合在一起本质上也只有线性函数的表达能力(例如,将多个线性方程组合在一起仅仅产生另一个线性方程)。因此,在激活函数是线性的情况下,相比于单隐藏层神经网络,包含多隐藏层的深度网络并没有增加表达能力。
2.1 优势
深度网络最主要优势是可以使用更加紧凑的方式来表达比浅层网络大得多的函数集合。比如处理对象是图像的时候,我们可以使用深度网络学习到“部分-整体”的分解关系。例如,第一层学习如何将图像中的像素组合在一起来检测边缘。第二层将边缘组合起来检测更长的轮廓或者简单的目标部件。当然在更深层次上,可以将这些轮廓进一步组合起来检测更加复杂的特征。
2.2 逐层贪婪训练方法
逐层贪婪训练方法是取得一定成功的一种方法。简单来说,逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。在每一步中,我们把已经训练好的前 k-1 层固定,然后增加第 k 层(也就是将我们已经训练好的前 k-1 的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器)。这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差)。
2.3 数据获取
虽然获取有标签数据的代价是昂贵的,但获取大量的无标签数据是容易的。自学习方法(self-taught learning)的潜力在于它能通过使用大量的无标签数据来学习到更好的模型。具体而言,该方法使用无标签数据来学习得到所有层(不包括用于预测标签的最终分类层 $W^{( l )}$ 的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
2.4 局部极值
当用无标签数据训练完网络后,相比于随机初始化而言,各层初始权重会位于参数空间中较好的位置上。然后我们可以从这些位置出发进一步微调权重。
参考文献
http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial
因为我们是朋友,所以你可以使用我的文字,但请注明出处:http://alwa.info